OUR THINKING
Establishing a Strong Cloud Foundation II: DevOps and SRE

While DevOps works to solve developmental problems and build solutions based on business needs, SRE is in charge of dealing with operational issues like infrastructural problems and security and production failures. Together, DevOps and SRE ensure system reliability and health for your cloud foundation.
In this blog, we take a look at what entails DevOp and SRE and how you can build a reliable, automated and secure cloud foundation.
Establishing DevOps
Before we get into how to establish DevOps, it’s important to understand what exactly we mean by DevOps and how it relates to cloud foundation. While the term itself comes from development and operations, AWS defines DevOps as “the combination of cultural philosophies, practices, and tools that increases an organization’s ability to deliver applications and services at high velocity”.
DevOps enables your business to evolve and improve products at a faster pace than organizations using traditional software development and infrastructure management processes. This speed is what gives your business the edge it needs to better serve customers and compete more effectively in the market.
DevOps also ensures a higher quality of application updates and infrastructure changes so you can reliably deliver at a more rapid pace while maintaining a positive experience for end users.
The DevOps model, due to its speed and scalability, keeps the innovation flywheel spinning and provides improved collaboration and combined workflows. It removes the barriers between two traditionally siloed teams, development and operations.
Role of SRE
Site Reliability Engineering (SRE) is when you use software tools to automate IT infrastructure tasks such as system management and application monitoring. Your business can use SRE to ensure that software applications remain reliable amidst updates from DevOps teams.
A Site Reliability Engineer works in close collaboration with development and operations teams. Alternatively, DevOps teams use SRE practices to monitor updates and respond to any system issues as they arise. A Site Reliability Engineer acknowledges that there is a high chance for software to fail, this allows the SRE team to plan an appropriate response and estimate the impact of potential downtime on business operations.
Observability 101
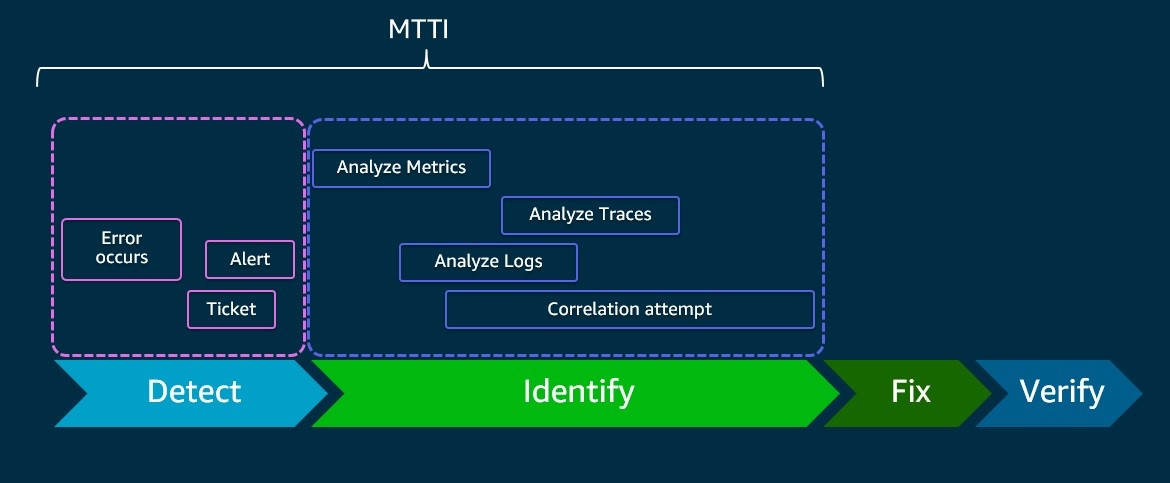
Observability, which describes how well you can understand what’s happening in a system, is an important DevOps and SRE tool. Observability solutions enable you to collect and analyze data from applications and infrastructure so you can understand their internal states and be alerted to – and resolve – issues quicker. Good observability leads to high site reliability, which makes it a topic that deserves our undivided attention.
The principle behind problem-solving is not about trying to eliminate all system errors. It’s about team preparedness when it comes to recognizing and responding to said errors as quickly and efficiently as possible. Observability allows you to do that by spotting problems as they arise so you can respond and resolve them quickly, before they disrupt user experience.
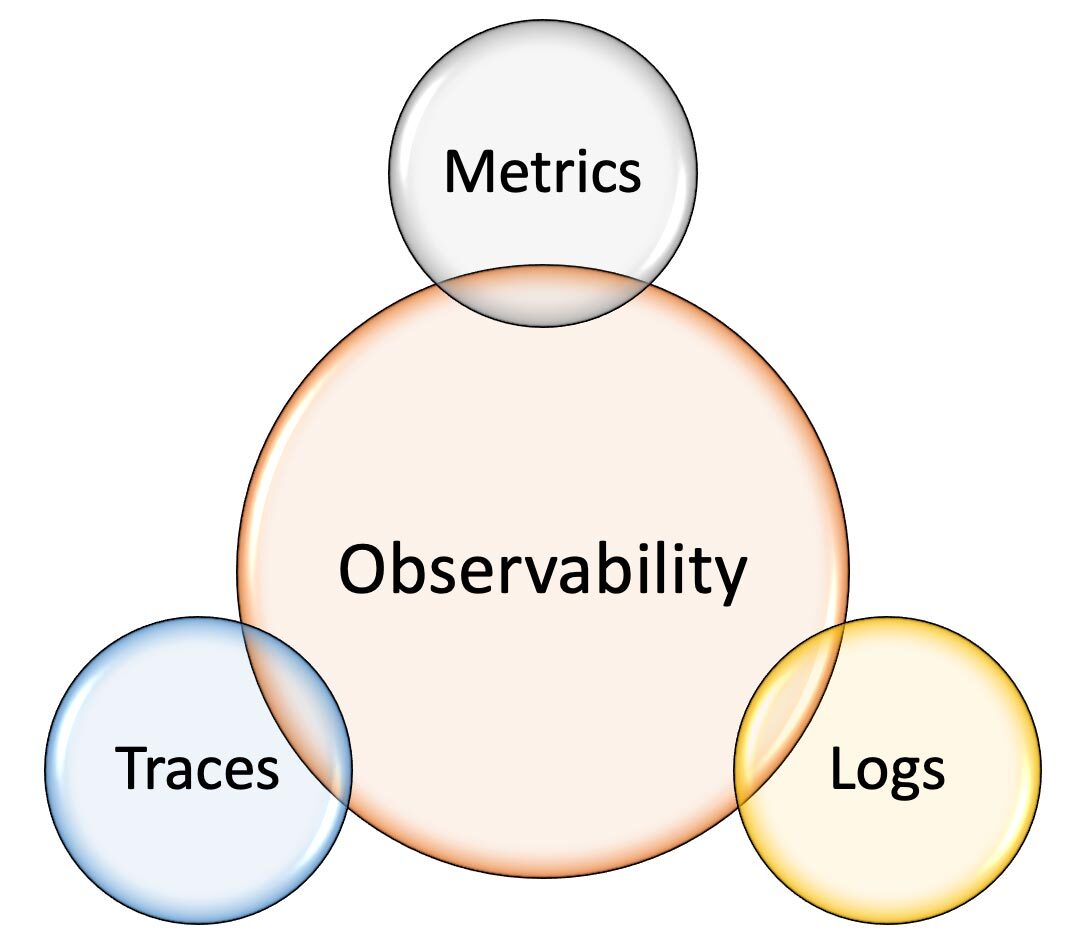
The three pillars of observability: monitoring (metrics), tracing and logging, ensure timely detection and investigation of system issues.
- Monitoring: Related to uptime as it refreshes at frequent intervals to check that a website is up and running.
- Tracing: Allows you to run things through many systems. For example, checking out a shopping cart involves assessing inventory, confirming product specifications (like size or colour), processing payment, etc.
- Logging: Uses stack trays that act as logs so in case a code runs an error you can check which line of code the error originated from.
DevOps, SRE and observability are not just about dashboards, alerts and governance. They’re also about the very culture of cloud computing and engineering. They prepare you to deal with inevitable fires that may arise and equip you with the best tools you need to extinguish them.
A common problem you may face is having a lot of disjointed observability tools that you do not know how to fully leverage. The open-source Accolite Observability Accelerator can help your business bootstrap its entire observability platform using AWS cloud native managed services. Contact us to get started!
If you’re looking for a platform to support your observability practices, check out OpenTelemetry, a collection of tools to help you analyze your software’s performance and behaviour.
Now that your Devops and SRE roles are in place, it is time to put them to the test. Our next blog on AWS GameDay discusses how you can improve preparedness in a fun, competitive and safe environment.


