OUR THINKING
Distributed Caches: The Guide You Need (Part II)

I had discussed two approaches for use cases 2 and 3. The code shared in this article showcases both approaches so that you can understand the pros and cons better.
For Approach 1, I’ve not applied a distributed lock so that I can demonstrate the potential data integrity issues when individual clients attempt to update a shared object.
Please note that the code is a very rudimentary timeline management service, missing many use cases.
It’s meant to showcase how a distributed cache enables atomic operations across a cluster in a very efficient manner.
The code example uses java data objects just to keep it simple, but in a system targeting high throughput there’s a very good probability that the data format string, e.g., json string, is passed along the pipeline to eliminate Object SerDe processing.
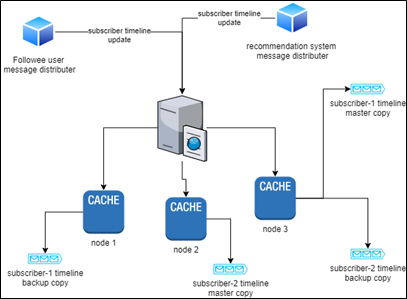
The diagram below shows the proposed architecture of this demo app:
Architecture
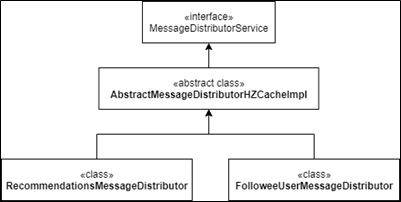
The class diagram for the main classes in this demo:
Class Diagram
The Abstract class above carries the bulk of the processing. I use the Guava collection’s Evicting Queue as the timeline repository.
Setting up Hazelcast:
Download Hazelcast (HZ) 5 platform from https://hazelcast.com/open-source-projects/downloads/
Setup your JAVA_HOME and PATH to the respective JDK/JRE folders. Ensure that you’re using the same JRE version as the code that you’ll deploy to the cluster. I’ve used JDK version 1.8.
Following steps are based on a windows setup. Replace paths based on your environment.
Add the following ‘timeline_cache’ map configuration to your HZ cluster config (<HZ installation folder>\config\hazelcast.xml) The cache’s in-memory format is OBJECT to make cluster processing more efficient.
<map name="timeline_cache">
<in-memory-format>OBJECT</in-memory-format>
<metadata-policy>CREATE_ON_UPDATE</metadata-policy>
<backup-count>1</backup-count>
<async-backup-count>0</async-backup-count>
<time-to-live-seconds>0</time-to-live-seconds>
<max-idle-seconds>0</max-idle-seconds>
<eviction eviction-policy="NONE" max-size-policy="PER_NODE" size="0"/>
<merge-policy batch-size="100">com.hazelcast.spi.merge.PutIfAbsentMergePolicy</merge-policy>
<cache-deserialized-values>INDEX-ONLY</cache-deserialized-values>
<statistics-enabled>true</statistics-enabled>
<per-entry-stats-enabled>false</per-entry-stats-enabled>
</map>
Timeline cache map
Starting up your HZ cluster
open up 4 command terminals...
terminal 1 and 2 - <HZ installation folder>\bin\hz-start.bat => you'll now have a 2 node local cluster
terminal 3 - <HZ installation folder>\management-center\bin\start.bat => the HZ management console connects to your local cluster. The logs mention the http port it’s started on. You can monitor your cluster from here.
terminal 4 - <HZ installation folder>\bin\hz-stop.bat => term 4 is only required when you wish to stop your HZ cluster. You can also Ctrl+C in term1,term2 and term3
Startup your cluster after deploying the required jars as mentioned in the next section.
starting HZ cluster
Notes on the classes:
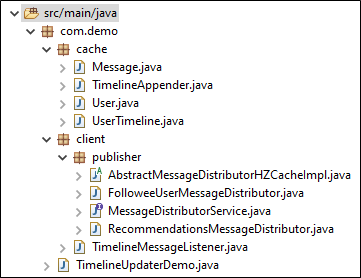
Here’s my package hierarchy. You can follow your own, just ensure that you make the appropriate changes to the code.
class hierarchy
The codebase depends on 2 libraries – Providing the maven dependencies below.
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>5.0</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version>
</dependency>
Dependency Libraries
Hazelcast’s runtime user code deployment feature doesn’t seem to work well with inner classes, which I’ve used. To avoid any runtime class discovery issues, I’ve copied the following 2 required jars to the HZ installation lib folder as a shortcut. You can also configure a classpath in HZ configuration so that you leave the installation’s lib folder clean.
Since the Hazelcast jars are already present in the HZ installation, you’ll only need to copy guava-31.0.1-jre.jar from your local maven repo to <HZ installation folder>\lib
After your build the codebase in this article, you’ll need to create a jar only containing the com.demo.cache package. Ensure to deploy this into the lib folder as well, similar to guava library.
TimelineUpdaterDemo => The main class of this Demo. The console messages should be self-explanatory. You pass it either…
“client_update” -> timeline updates are performed by the Client nodes,ie, RecommendationMessageDistributor and FolloweeUserMessageDistributor
“cluster_update” => timeline updates are performed by TimelineAppender (EntryProcessor) which RecommendationMessageDistributor and FolloweeUserMessageDistributor push to the cache.
package com.demo;
import java.util.List;
import java.util.Scanner;
import java.util.UUID;
import com.demo.cache.User;
import com.demo.cache.UserTimeline;
import com.demo.client.TimelineMessageListener;
import com.demo.client.publisher.AbstractMessageDistributorHZCacheImpl;
import com.demo.client.publisher.AbstractMessageDistributorHZCacheImpl.DistributionMode;
import com.demo.client.publisher.FolloweeUserMessageDistributor;
import com.demo.client.publisher.RecommendationsMessageDistributor;
import com.google.common.collect.Lists;
import com.hazelcast.client.HazelcastClient;
import com.hazelcast.client.config.ClientConfig;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.map.IMap;
public class TimelineUpdaterDemo {
private static final String TIMELINE_CACHE_NAME = "timeline_cache";
public static void main(String[] args) throws Exception {
if (args.length==0) {
System.out.println ("Pls pass either 'client_update' or 'cluster_update' as a parameter\n");
System.out.println ("client_update => updates the user timeline at the Client node. Fetch from cache->Update->Put back in cache");
System.out.println ("cluster_update => Code with data is pushed to the Custer to atomically update the timeline");
System.exit(1);
}
ClientConfig clientConfig = new ClientConfig();
clientConfig.getNetworkConfig().addAddress("127.0.0.1");
HazelcastInstance client = HazelcastClient.newHazelcastClient(clientConfig);
System.out.println(clientConfig.toString());
// add a timeline listener to see timeline updates
IMap<User,UserTimeline> timelineCache = client.getMap(TIMELINE_CACHE_NAME);
UUID listenerId = timelineCache.addEntryListener(new TimelineMessageListener(), true);
DistributionMode distributionMode = null;
switch (args[0]) {
case "client_update" :
distributionMode = AbstractMessageDistributorHZCacheImpl.DistributionMode.Client;
break;
case "cluster_update" :
distributionMode = AbstractMessageDistributorHZCacheImpl.DistributionMode.Cluster;
break;
}
FolloweeUserMessageDistributor fmd = new FolloweeUserMessageDistributor(timelineCache,distributionMode);
RecommendationsMessageDistributor rmd = new RecommendationsMessageDistributor(timelineCache,distributionMode);
User subscriber = new User(User.Type.User, "subscriber-neo");
List<User> subscriberList = Lists.newArrayList(subscriber);
System.out.println("\nmessages in the timeline cache are printed in reverse chronological order on System.err");
System.out.println("Timeline updation mode : " + distributionMode);
System.out.println("\nhit enter to start...");
System.out.println("hit enter again to stop!");
Scanner scanner = new Scanner(System.in);
scanner.nextLine();
fmd.initialize(subscriberList);
rmd.initialize(subscriberList);
scanner.nextLine();
scanner.close();
fmd.shutdown();
rmd.shutdown();
timelineCache.removeEntryListener(listenerId);
HazelcastClient.shutdownAll();
}
}
TimelineUpdaterDemo.java
TimelineMessageListener => An Hazelcast EventListener Impl listening to changes in the timeline cache. It prints the timeline in the console so that you can see what’s happening.
package com.demo.client;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import com.demo.cache.Message;
import com.demo.cache.UserTimeline;
import com.hazelcast.core.EntryEvent;
import com.hazelcast.map.listener.EntryUpdatedListener;
public class TimelineMessageListener implements EntryUpdatedListener<String, UserTimeline> {
private DateTimeFormatter dtf = DateTimeFormatter.ofPattern("ss.SSS");
/**
* when a timeline updated notification is received
* print the current timeline in reverse chronological order
*/
public void entryUpdated(EntryEvent<String, UserTimeline> event) {
String ts = LocalDateTime.now().format(dtf);
UserTimeline newTimeline = event.getValue();
Message[] messages = newTimeline.getTimelineMessages();
// print the current seconds in the output to help understand the time sequence
System.err.print(ts + " => ");
for (int ctr=messages.length-1;ctr>=0;ctr--)
System.err.print(messages[ctr] + " | ");
System.err.println("");
}
}
TimelineMessageListener.java
TimelineAppender => An implementation of the EventProcessor to update the subscriber’s timeline directly in the cache node, in an atomic manner.
package com.demo.cache;
import java.util.Map.Entry;
import com.hazelcast.map.EntryProcessor;
public class TimelineAppender implements EntryProcessor<User, UserTimeline, Boolean> {
private static final long serialVersionUID = 5879348250751813902L;
private Message msg;
public TimelineAppender(Message msg) {
this.msg = msg;
}
public Boolean process(Entry<User,UserTimeline> entry) {
UserTimeline tl = entry.getValue();
tl.addMessage(msg);
// HZ requires an explicit set even if value object is mutable
// triggers propagation
entry.setValue(tl);
// result of the method is not required, therefore return null
return null;
}
}
TimelineAppender.java
Message, User and UserTimeline => Data objects
package com.demo.cache;
import java.io.Serializable;
public class Message implements Serializable{
private static final long serialVersionUID = -4003664792323373086L;
private User user;
private String message;
public Message(User user, String message) {
super();
this.user = user;
this.message = message;
}
@Override
public String toString() {
return user + "=>\"" + message + "\"";
}
public User getUser() {
return user;
}
public String getMessage() {
return message;
}
}
Message.java
package com.demo.cache;
import java.io.Serializable;
import java.util.Objects;
public class User implements Serializable {
private static final long serialVersionUID = 1444377538666731199L;
public enum Type {
User, Recommendation {
@Override
public String toString() {
return "Reco";
}
}
};
private Type userType;
private String userName;
public User(Type userType, String userName) {
super();
this.userType = userType;
this.userName = userName;
}
public Type getUserType() {
return userType;
}
public String getUserName() {
return userName;
}
@Override
public String toString() {
return userType + ":" + userName;
}
@Override
public int hashCode() {
return Objects.hash(userName, userType);
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
User other = (User) obj;
return Objects.equals(userName, other.userName) && userType == other.userType;
}
}
User.java
package com.demo.cache;
import java.io.Serializable;
import com.google.common.collect.EvictingQueue;
public class UserTimeline implements Serializable {
private static final long serialVersionUID = 8447650890107641084L;
private User user;
private EvictingQueue<Message> timelineMessages;
public UserTimeline(User user, int timelineCacheSize) {
this.user = user;
this.timelineMessages = EvictingQueue.create(timelineCacheSize);
}
public void addMessage(Message msg) {
timelineMessages.add(msg);
}
public User getUser() {
return user;
}
public Message[] getTimelineMessages() {
return timelineMessages.toArray(new Message[timelineMessages.size()]);
}
}
UserTimeline.java
MessageDistributorService => an interface to define the Message distributor service instances. It manages the timeline of subscribers it’s assigned to. It can receive messages from its respective source and update the timeline of the subscriber in an atomic manner.
package com.demo.client.publisher;
import java.util.List;
import com.demo.cache.Message;
import com.demo.cache.User;
/**
* Instances of MessageDistributorService will manage a set of subscribers
* The message sources can be varied
*
*/
public interface MessageDistributorService {
List<User> getSubscribers();
/**
* @param message message to be pushed to subscribers managed by this node
*/
void distributeMessage(Message message);
/**
* @param subscriberList user list managed by this node
*/
void initialize(List<User> subscriberList);
void shutdown();
}
MessageDistributorService.java
RecommendationsMessageDistributor => A Recommendation service that pushes recommendation messages to its subscriber list. Multiple nodes of the same Recommendation system manage their distinct set of subscribers.
package com.demo.client.publisher;
import java.util.List;
import java.util.Random;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
import com.demo.cache.Message;
import com.demo.cache.User;
import com.demo.cache.UserTimeline;
import com.hazelcast.map.IMap;
public class RecommendationsMessageDistributor extends AbstractMessageDistributorHZCacheImpl {
private Random random = new Random(System.currentTimeMillis());
private ScheduledExecutorService scheduler;
public RecommendationsMessageDistributor(IMap<User, UserTimeline> timelineCache, DistributionMode mode) {
super(timelineCache, mode);
}
@Override
public void shutdown() {
scheduler.shutdownNow();
super.shutdown();
}
@Override
public void distributeMessage(Message message) {
super.distributeMessage(message);
}
@Override
public void initialize(List<User> subscriberList) {
super.initialize(subscriberList);
scheduler = Executors.newSingleThreadScheduledExecutor();
scheduler.scheduleAtFixedRate(new MessageGenerator(User.Type.Recommendation), random.nextInt(500), random.nextInt(100),
TimeUnit.MILLISECONDS);
}
}
RecommendationsMessageDistributor.java
FolloweeUserMessageDistributor => Node listens to messages from say, an Influencer, and pushes the messages to their subscribers. You could have multiple nodes listening to the same Influencer but managing a distinct set of subscribers.
package com.demo.client.publisher;
import java.util.List;
import java.util.Random;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
import com.demo.cache.Message;
import com.demo.cache.User;
import com.demo.cache.UserTimeline;
import com.hazelcast.map.IMap;
public class FolloweeUserMessageDistributor extends AbstractMessageDistributorHZCacheImpl {
private Random random = new Random(System.currentTimeMillis());
private ScheduledExecutorService scheduler;
public FolloweeUserMessageDistributor(IMap<User,UserTimeline> timelineCache,DistributionMode mode) {
super(timelineCache,mode);
}
@Override
public void shutdown() {
scheduler.shutdownNow();
super.shutdown();
}
@Override
public void distributeMessage(Message message) {
super.distributeMessage(message);
}
@Override
public void initialize(List<User> subscriberList) {
super.initialize(subscriberList);
scheduler = Executors.newSingleThreadScheduledExecutor();
scheduler.scheduleAtFixedRate(new MessageGenerator(User.Type.User), random.nextInt(500), random.nextInt(100),
TimeUnit.MILLISECONDS);
}
}
Followeeusermessagedistributor.java
In this demo codebase, both RecommendationsMessageDistributor and FolloweeUserMessageDistributor start as a single instance and send messages to their subscriber list with random timing. They extend from AbstractMessageDistributorHZCacheImpl which handles the actual processing.
package com.demo.client.publisher;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.Collections;
import java.util.List;
import java.util.Random;
import com.demo.cache.Message;
import com.demo.cache.TimelineAppender;
import com.demo.cache.User;
import com.demo.cache.UserTimeline;
import com.hazelcast.map.IMap;
public abstract class AbstractMessageDistributorHZCacheImpl implements MessageDistributorService {
public static enum DistributionMode {
Client, Cluster
};
protected List<User> subscriberList;
IMap<User, UserTimeline> timelineCache;
private DistributionMode distributionMode;
public AbstractMessageDistributorHZCacheImpl(IMap<User, UserTimeline> timelineCache, DistributionMode mode) {
this.timelineCache = timelineCache;
this.distributionMode = mode;
}
@Override
public List<User> getSubscribers() {
return Collections.unmodifiableList(subscriberList);
}
@Override
public void distributeMessage(Message message) {
for (User subscriber : subscriberList) {
switch (distributionMode) {
case Client:
UserTimeline subscriberTimeline = timelineCache.get(subscriber);
subscriberTimeline.addMessage(message);
timelineCache.put(subscriber, subscriberTimeline);
break;
case Cluster:
timelineCache.executeOnKey(subscriber, new TimelineAppender(message));
break;
}
}
}
@Override
public void initialize(List<User> subscriberList) {
this.subscriberList = subscriberList;
// check if the subscribers are initialized in the cache.
// if not create their entries
for (User subscriber : subscriberList) {
timelineCache.computeIfAbsent(subscriber, (k) -> new UserTimeline(k, 10));
}
}
@Override
public void shutdown() {
timelineCache = null;
}
public class MessageGenerator implements Runnable {
private Random random = new Random(System.currentTimeMillis());
private DateTimeFormatter dtf = DateTimeFormatter.ofPattern("ss.SSS");
private User.Type userType;
public MessageGenerator(User.Type userType) {
this.userType = userType;
}
@Override
public void run() {
User user = new User(userType, userType.toString()+"-" + random.nextInt(10));
String ts = LocalDateTime.now().format(dtf);
Message message = new Message(user, "message at " + ts);
System.out.println(message);
System.out.flush();
distributeMessage(message);
}
}
}
AbstractMessageDistributorHZCacheImpl.java
The main message publishing code is located at AbstractMessageDistributorHZCacheImpl. distributeMessage(). This method uses either Client or Cluster update modes based on the command line toggle when running the demo.
Familiarize yourself with the code and then give it a run. I’ve explained the output you’ll see in the console below. Note that TimelineMessageListener prints the timeline on StdErr.
The output snapshot below is for approach 1 – “client_update”
You can see that the message “User:User-6=>”message at 46.107″ is lost between updates – see the log output marked in red. Never a good thing! This would not occur had we incorporated a distributed lock but that brings a whole set of additional headaches, i.e., management of the granular locks themselves.
User:User-3=>”message at 46.095″ è printed by the Followee instance when it generates a message
User:User-6=>”message at 46.107″
Reco:Reco-0=>”message at 46.107″ è printed by the Recommendation instance when it generates a message
The TimelineListener prints the logs below when it registers a timeline change.
The format is <second.millisecond> => timeline messages in reverse chronological order
46.108 => User:User-3=>”message at 46.095″ | User:User-3=>”message at 00.946″ | User:User-6=>”message at 00.900″ | User:User-4=>”message at 00.837″ | User:User-0=>”message at 00.790″ | User:User-7=>”message at 00.744″ | User:User-7=>”message at 00.682″ | User:User-8=>”message at 00.635″ | User:User-5=>”message at 00.589″ | User:User-9=>”message at 00.528″ |
46.110 => User:User-6=>”message at 46.107″ | User:User-3=>”message at 46.095″ | User:User-3=>”message at 00.946″ | User:User-6=>”message at 00.900″ | User:User-4=>”message at 00.837″ | User:User-0=>”message at 00.790″ | User:User-7=>”message at 00.744″ | User:User-7=>”message at 00.682″ | User:User-8=>”message at 00.635″ | User:User-5=>”message at 00.589″ |
46.112 => Reco:Reco-0=>”message at 46.107″ | User:User-3=>”message at 46.095″ | User:User-3=>”message at 00.946″ | User:User-6=>”message at 00.900″ | User:User-4=>”message at 00.837″ | User:User-0=>”message at 00.790″ | User:User-7=>”message at 00.744″ | User:User-7=>”message at 00.682″ | User:User-8=>”message at 00.635″ | User:User-5=>”message at 00.589″ |
User:User-3=>"message at 46.095" printed by the Followee instance when it generates a message
User:User-6=>"message at 46.107"
Reco:Reco-0=>"message at 46.107" printed by the Recommendation instance when it generates a message
The TimelineListener prints the logs below when it registers a timeline change.
The format is <second.millisecond> => timeline messages in reverse chronological order
46.108 => User:User-3=>"message at 46.095" | User:User-3=>"message at 00.946" | User:User-6=>"message at 00.900" | User:User-4=>"message at 00.837" | User:User-0=>"message at 00.790" | User:User-7=>"message at 00.744" | User:User-7=>"message at 00.682" | User:User-8=>"message at 00.635" | User:User-5=>"message at 00.589" | User:User-9=>"message at 00.528" |
46.110 => User:User-6=>"message at 46.107" | User:User-3=>"message at 46.095" | User:User-3=>"message at 00.946" | User:User-6=>"message at 00.900" | User:User-4=>"message at 00.837" | User:User-0=>"message at 00.790" | User:User-7=>"message at 00.744" | User:User-7=>"message at 00.682" | User:User-8=>"message at 00.635" | User:User-5=>"message at 00.589" |
46.112 => Reco:Reco-0=>"message at 46.107" | User:User-3=>"message at 46.095" | User:User-3=>"message at 00.946" | User:User-6=>"message at 00.900" | User:User-4=>"message at 00.837" | User:User-0=>"message at 00.790" | User:User-7=>"message at 00.744" | User:User-7=>"message at 00.682" | User:User-8=>"message at 00.635" | User:User-5=>"message at 00.589" |
client_update
The output snapshot below is for approach 1 – “cluster_update”
The EntryProcessor is pushed to the cluster to update the timeline in an atomic manner. The logs clearly demonstrate that proper sequencing of timeline updates occur without any message losses. The Distributed cache atomic update is ensured by the EntryProcessor since the Hazelcast engine applies a Distributed cache write synchronization across all the nodes that need to be updated.
Reco:Reco-3=>”message at 47.383″
47.388 => Reco:Reco-3=>”message at 47.383″ | User:User-3=>”message at 47.352″ | Reco:Reco-5=>”message at 47.338″ | User:User-8=>”message at 47.306″ | User:User-9=>”message at 47.257″ | User:User-2=>”message at 47.213″ |
User:User-8=>”message at 47.399″
Reco:Reco-2=>”message at 47.399″
47.404 => User:User-8=>”message at 47.399″ | Reco:Reco-3=>”message at 47.383″ | User:User-3=>”message at 47.352″ | Reco:Reco-5=>”message at 47.338″ | User:User-8=>”message at 47.306″ | User:User-9=>”message at 47.257″ | User:User-2=>”message at 47.213″ |
47.406 => Reco:Reco-2=>”message at 47.399″ | User:User-8=>”message at 47.399″ | Reco:Reco-3=>”message at 47.383″ | User:User-3=>”message at 47.352″ | Reco:Reco-5=>”message at 47.338″ | User:User-8=>”message at 47.306″ | User:User-9=>”message at 47.257″ | User:User-2=>”message at 47.213″ |
Reco:Reco-3=>"message at 47.383"
47.388 => Reco:Reco-3=>"message at 47.383" | User:User-3=>"message at 47.352" | Reco:Reco-5=>"message at 47.338" | User:User-8=>"message at 47.306" | User:User-9=>"message at 47.257" | User:User-2=>"message at 47.213" |
User:User-8=>"message at 47.399"
Reco:Reco-2=>"message at 47.399"
47.404 => User:User-8=>"message at 47.399" | Reco:Reco-3=>"message at 47.383" | User:User-3=>"message at 47.352" | Reco:Reco-5=>"message at 47.338" | User:User-8=>"message at 47.306" | User:User-9=>"message at 47.257" | User:User-2=>"message at 47.213" |
47.406 => Reco:Reco-2=>"message at 47.399" | User:User-8=>"message at 47.399" | Reco:Reco-3=>"message at 47.383" | User:User-3=>"message at 47.352" | Reco:Reco-5=>"message at 47.338" | User:User-8=>"message at 47.306" | User:User-9=>"message at 47.257" | User:User-2=>"message at 47.213" |
Cluster_update
I hope this deep dive into a very important feature set of distributed caches, i.e, distributed compute has made you eager to learn more about dist caches and their features that go beyond mere distributed data storage!
Read the full blog here.


